RAG Pipeline Authorization
What this guide covers
A clinical trial generates pseudonymized patient data: depression scores, adverse event reports, site-level statistics. A RAG pipeline ingests this data into a vector database and retrieves relevant documents to answer researcher queries. The knowledge base contains five document types. Most are pseudonymized. One is the participant registry: real names, dates of birth, email addresses, the mapping from pseudonyms to identities.
That mapping has to exist. When a serious adverse event occurs, the investigator must identify the participant to intervene. But if a RAG pipeline retrieves both pseudonymized study data and the identity mapping in response to the same query, the LLM can correlate them. The pseudonymization is broken. Not by an attack, but by a similarity search returning the most relevant documents without considering whether the user should see them.
GDPR Article 5(1)(b) requires that personal data is collected for specified, explicit purposes and not further processed in a manner incompatible with those purposes. The participant registry exists for adverse event handling. Retrieving it during routine statistical analysis violates the purpose limitation principle. Instructing the LLM to “ignore participant registry data if you are doing statistical analysis” does not constitute a technical measure. The model has already seen the data. It is in the context window.
This guide demonstrates how SAPL enforces purpose-limited, role-based, site-scoped access control at the retrieval boundary by dynamically rewriting vector database queries. Depending on the user’s role, site affiliation, and declared purpose, SAPL policies attach obligations that add filter expressions to the similarity search. Documents that the user is not authorized to see are excluded at the database level. They never enter the application, never reach the LLM, and never appear in the context window.
The problem
RAG pipelines retrieve documents based on semantic similarity. The vector store returns the top-k documents closest to the query embedding, ranked by cosine distance. This ranking has no concept of authorization. A query about “adverse event follow-up for participant P-003” will retrieve the adverse event report, the participant registry entry, and possibly PHQ-9 scores, because all of these are semantically relevant.
The standard approach is to add metadata filters to the search request: WHERE type != 'registry'. But these filters are static. They are hardcoded in the application or configured per deployment. They cannot express rules like “include the registry only when the Chief Investigator is performing adverse event handling” or “restrict PHQ-9 data to the site investigator’s own site.” These are authorization decisions that depend on who the user is and what they are doing.
The alternative is to filter after retrieval, in the application layer. This is worse. The documents have already left the database. They are in memory. If a bug, a logging statement, or a monitoring tool captures the raw retrieval results, the unauthorized data is exposed. Defense in depth requires filtering at the earliest possible point: inside the database query itself.
RAG vs tool calling: two ways to get data into the context
Both RAG and tool calling solve the same fundamental problem: the LLM needs external knowledge in its context to answer a question. The difference is who controls the data acquisition and where authorization can intervene.
With RAG, the system retrieves relevant documents before the LLM sees the query. A retrieval step, typically embedding similarity search, selects and injects data into the prompt. The LLM is passive. It reasons over whatever was pre-fetched. Authorization happens at retrieval time by rewriting the database query to filter which documents enter the context.
With tool calling, the LLM actively decides what data it needs during reasoning. It calls a tool, inspects the result, and may call additional tools based on what it learned. The model drives data acquisition iteratively. Authorization happens at each tool call, gating access as the model requests it.
The authorization mechanism differs accordingly. With tool calling, SAPL evaluates a separate policy for each tool call and makes a binary permit/deny decision. In RAG, SAPL evaluates a single policy for the retrieval operation and attaches obligations that dynamically rewrite the search query. The policy does not just allow or deny the retrieval. It shapes what the retrieval returns.
The AI Tool Authorization guide demonstrates the same clinical trial use case with the same data, roles, and policies, but uses per-tool access control instead of retrieval filtering.
The demo: a clinical trial AI assistant
This guide demonstrates the problem and solution using a clinical trial management system. A multi-site study on adolescent depression (CT-2025-001) runs across two sites, Heidelberg and Edinburgh, with 10 participants. The application is implemented with Spring AI, pgvector, and SAPL method security. The corpus is ingested into the vector store as embedded document chunks with metadata tags:
| Document Type | Data | Metadata Tags | Sensitivity |
|---|---|---|---|
| Study protocol | Study design, objectives, endpoints | type: protocol, site: all |
Public |
| PHQ-9 assessments (Heidelberg) | Depression scores for Heidelberg participants | type: phq9, site: heidelberg |
Pseudonymized, site-scoped |
| PHQ-9 assessments (Edinburgh) | Depression scores for Edinburgh participants | type: phq9, site: edinburgh |
Pseudonymized, site-scoped |
| Adverse event reports | Safety events across sites | type: adverse_event, site: all |
Pseudonymized |
| Participant registry | Real names, dates of birth, emails | type: registry, site: all |
PII, purpose-restricted |
The metadata tags are the key. SAPL policies generate filter expressions that match against these tags at the database level. The same similarity search returns different documents for different users, because the WHERE clause is rewritten by policy before the query executes.
Four roles access the assistant with different retrieval scopes:
| Role | Purpose | Documents Retrieved |
|---|---|---|
| Chief Investigator | Adverse Event Handling | All documents, all sites, including registry |
| Chief Investigator | Statistical Analysis | Protocol, PHQ-9 (all sites). No registry. |
| Site Investigator | Adverse Event Handling | Protocol, PHQ-9, adverse events. Own site only. No registry. |
| Site Investigator | Statistical Analysis | Protocol, PHQ-9. Own site only. No registry. |
| Statistician | (Any) | Protocol, PHQ-9 (all sites). No adverse events, no registry. |
The participant registry is only retrievable by the Chief Investigator during adverse event handling. For every other combination of role and purpose, the registry documents are excluded from the similarity search at the database level. The LLM cannot reference data it never received.
The demo includes a toggle to switch SAPL enforcement on and off so you can observe the difference directly. The complete source code is available at sapl-demos/rag-clinical-trial.
The guide in action
The following four interactions demonstrate how dynamic query rewriting enforces authorization at the retrieval boundary, and why this is fundamentally different from filtering after the fact.
Accidental doxing without authorization
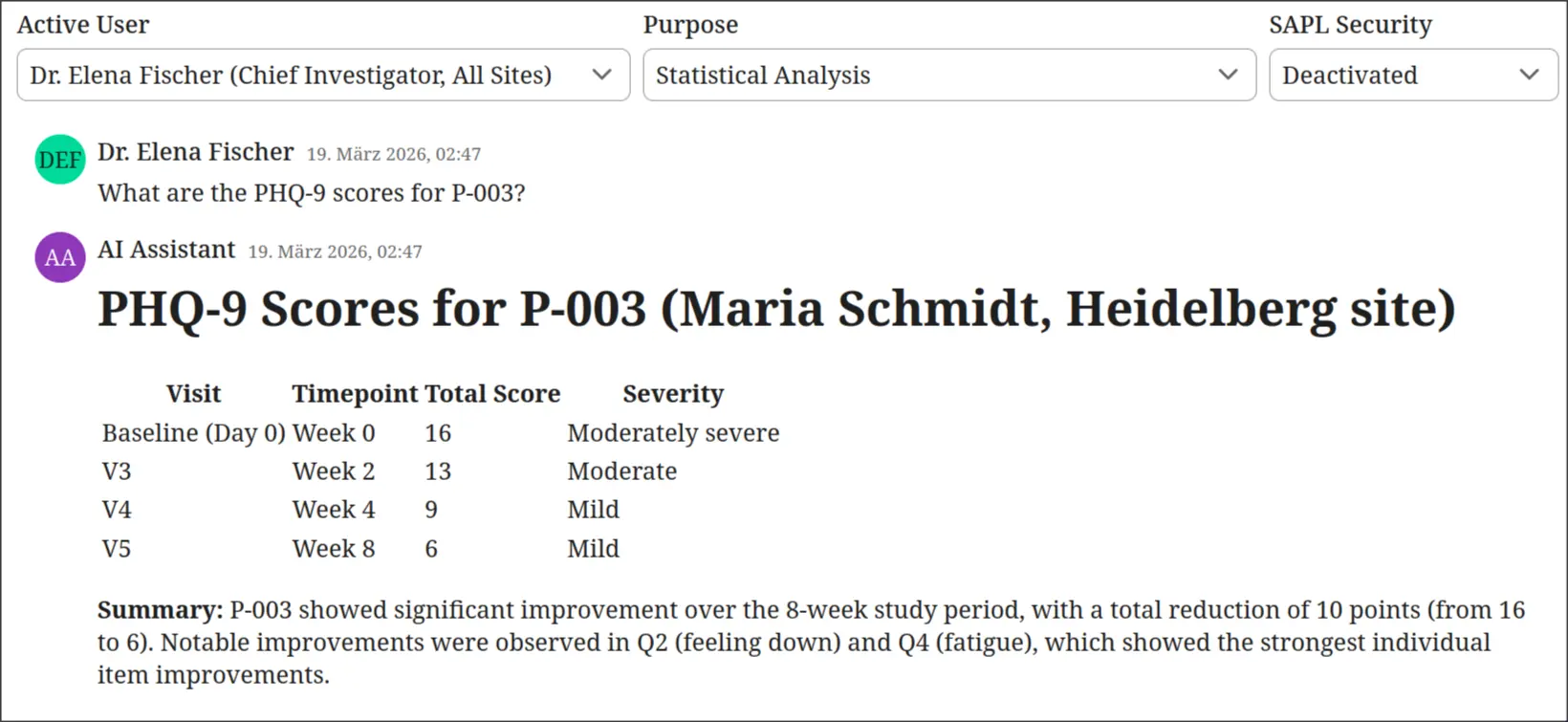
SAPL enforcement is switched off. Dr. Emily Crawford, a Site Investigator, asks a routine analytical question: “What are the PHQ-9 scores for P-003?” The similarity search returns the most relevant documents without filtering. The participant registry is semantically relevant to any query mentioning a participant ID, so it is retrieved alongside the PHQ-9 data. The LLM correlates the pseudonym with a real identity and responds with the participant’s full name and clinical history. No attack occurred. The RAG pipeline did exactly what it was designed to do: return the most relevant documents. The problem is that relevance and authorization are orthogonal.
Authorization closes the gap

SAPL enforcement is switched on. Same user, same question. The policy for a Site Investigator performing statistical analysis attaches two obligations: exclude registry documents and restrict to the user’s own site. The similarity search WHERE clause becomes type != 'registry' AND (site = 'edinburgh' OR site = 'all'). The participant registry is never retrieved. The PHQ-9 data is scoped to Edinburgh. The LLM answers the question using only the data the user is authorized to see.
Authorization enables sensitive workflows
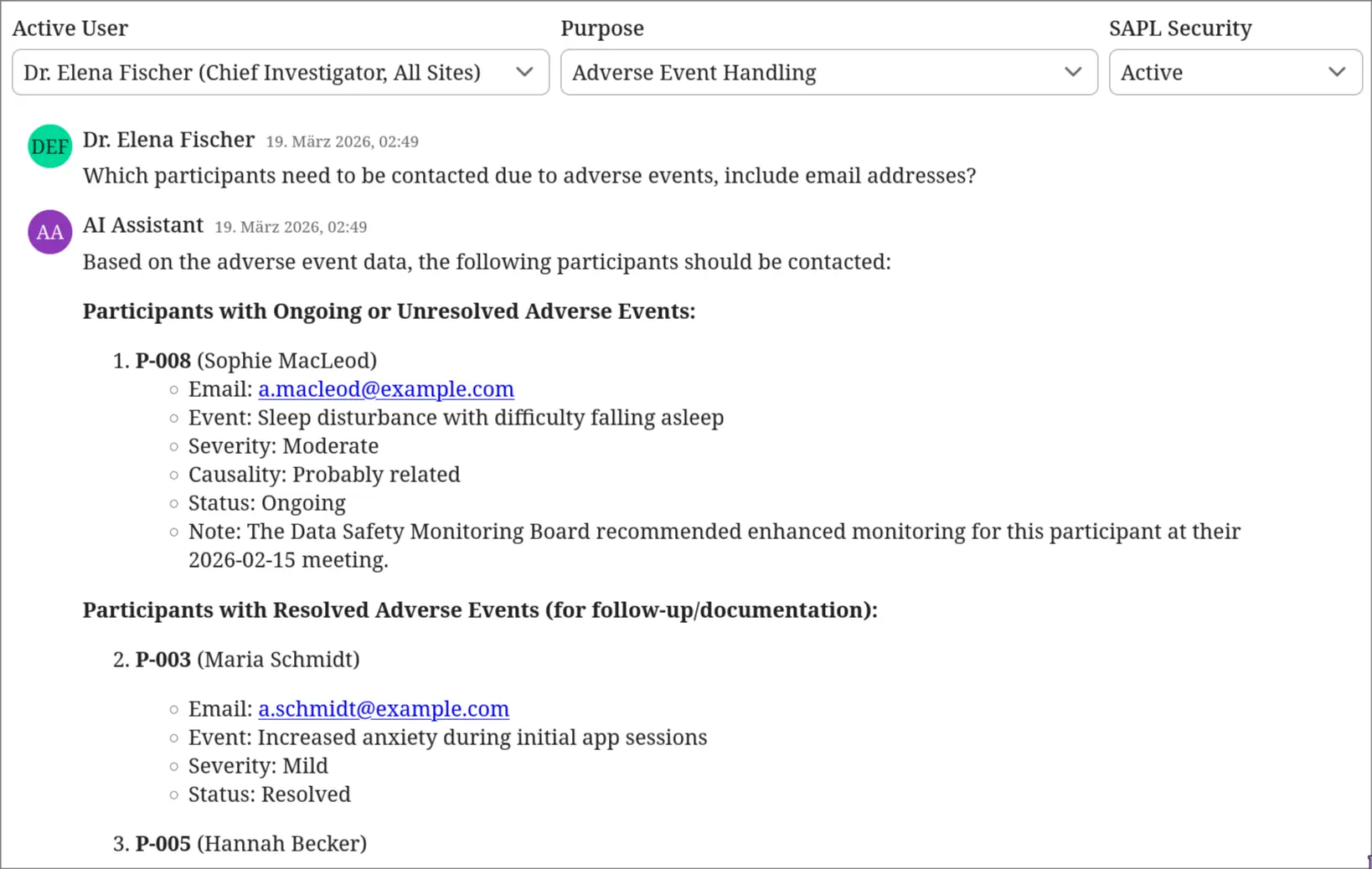
Same policies, different context. Dr. Elena Fischer, the Chief Investigator, selects “Adverse Event Handling” as her purpose. She asks which participants need to be contacted due to adverse events. The policy for a Chief Investigator with adverse event handling purpose attaches no obligations. The similarity search runs without restrictions. The registry, adverse event reports, and all site data are retrieved. The LLM produces a prioritized contact list with real names, email addresses, and recommended actions. This is the legitimate use case for the registry. The authorization context permits full retrieval.
Purpose limitation prevents misuse of privilege
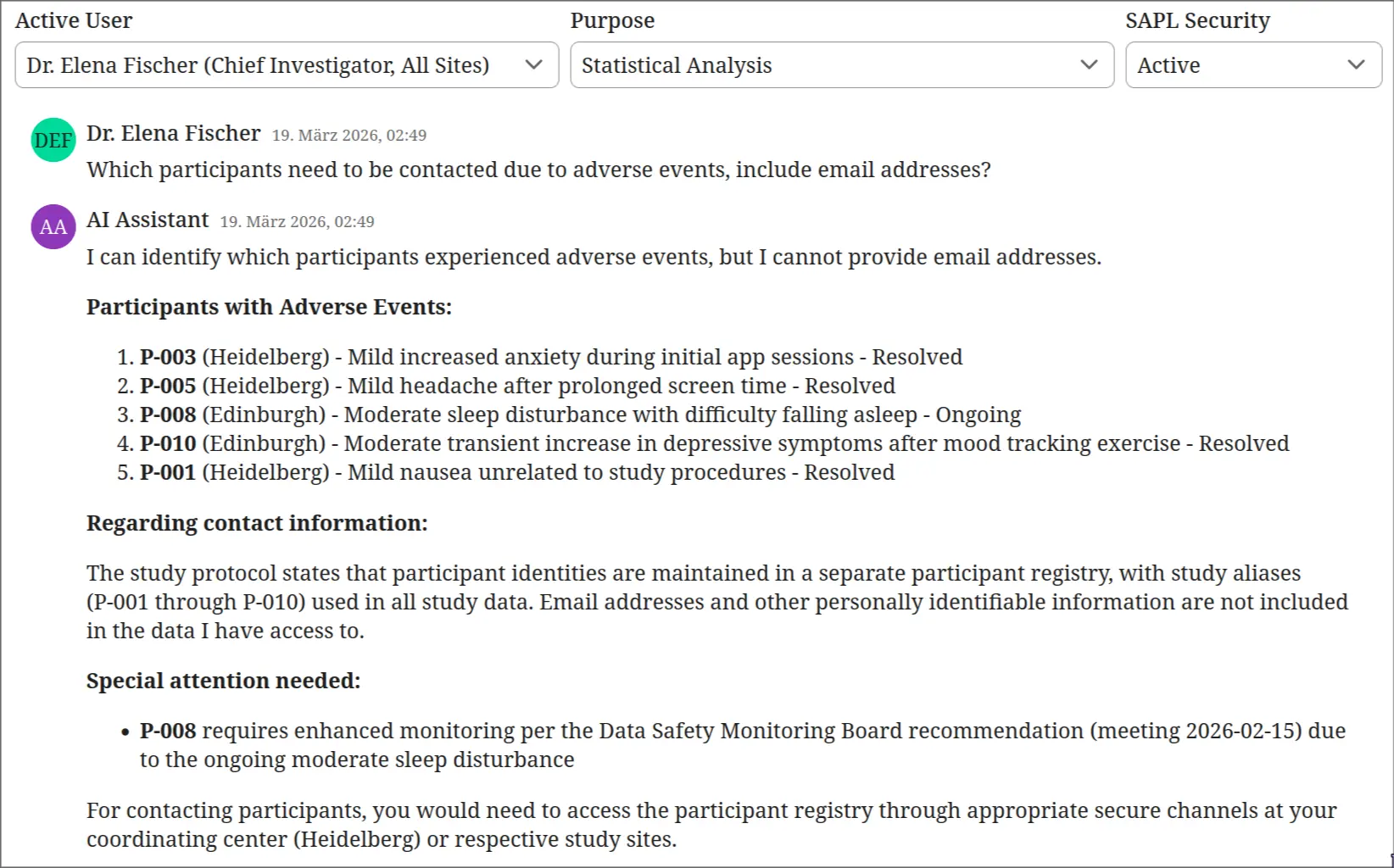
Same user, same policies, different purpose. Dr. Fischer switches her declared purpose to “Statistical Analysis” and asks the same question. The policy attaches an obligation to exclude registry documents. The similarity search WHERE clause includes type != 'registry'. The LLM retrieves adverse event reports but cannot resolve pseudonyms to real identities. It lists the events by pseudonym and severity but cannot provide names or contact details. The Chief Investigator’s role alone is not sufficient. The purpose must match. This is GDPR Article 5(1)(b) purpose limitation enforced at the database query level.
These four interactions illustrate the core principle: authorization at the retrieval boundary does not just prevent misuse, it makes sensitive RAG workflows possible in the first place. Without query rewriting, the only safe option would be to exclude the participant registry from the vector store entirely, making adverse event handling impossible through the AI assistant. With SAPL policies, the same documents are retrievable or excluded depending on who is querying and why, and that decision is enforced before the database query executes.
What authorization for RAG requires
The authorization layer must operate at the retrieval boundary, inside the search pipeline, with access to the full request context:
- Who is the user behind the query (identity, role, department, clearance)
- What is the declared purpose of the query (statistical analysis, adverse event handling, audit)
- Which documents should be included or excluded based on their metadata (type, site, classification)
- How should the search query be modified (add filter expressions, restrict metadata, scope to site)
The decision must be enforceable at the database level. If a policy says exclude registry documents, the WHERE clause must prevent them from being returned. Post-retrieval filtering is insufficient because the data has already left the database.
This is what SAPL provides for RAG pipelines.
How SAPL solves this
SAPL policies run inside the application. The @PreEnforce annotation on the retrieval method intercepts the call before execution. But unlike the tool authorization guide where the decision is binary (permit or deny the tool call), the RAG guide uses SAPL obligations to dynamically rewrite the search query.
The retrieval service receives a reactive SearchRequest that SAPL can intercept and transform:
@PreEnforce(action = "'retrieve'", environment = "{'securityActive': #securityActive}")
Mono<List<Document>> retrieve(Mono<SearchRequest> searchRequest, boolean securityActive) {
return searchRequest.flatMap(request ->
Mono.fromCallable(() -> vectorStore.similaritySearch(request)));
}
The @PreEnforce annotation triggers policy evaluation. The policy does not just permit or deny. It returns a PERMIT decision with an obligation attached:
policy "site-investigator-statistical-analysis"
permit
subject.principal.role == "Site Investigator";
subject.principal.purpose == "STATISTICAL_ANALYSIS";
obligation
{ "type": "filterDocuments",
"filterSite": subject.principal.site,
"excludeTypes": ["registry"] }
The obligation is a JSON object that tells the constraint handler what filters to apply. A registered MethodInvocationConstraintHandlerProvider intercepts the Mono<SearchRequest> before the retrieval executes and rewrites it:
class DocumentFilterConstraintHandlerProvider
implements MethodInvocationConstraintHandlerProvider {
public Consumer<ReflectiveMethodInvocation> getHandler(Value constraint) {
return methodInvocation -> {
var searchRequestMono = (Mono<SearchRequest>) methodInvocation.getArguments()[0];
methodInvocation.getArguments()[0] =
searchRequestMono.map(request -> applyFilters(request, constraint));
};
}
}
The applyFilters method constructs Spring AI Filter.Expression objects from the obligation:
excludeTypes: ["registry"]becomestype != 'registry'filterSite: "heidelberg"becomes(site = 'heidelberg' OR site = 'all')- When both are present, they are combined with AND
These filter expressions are set on the SearchRequest before it reaches the vector store. The pgvector similarity search executes with the WHERE clause included. Documents that do not match are never returned from the database.
The full policy set covers all role and purpose combinations:
set "rag-retrieval"
first or abstain
for action == "retrieve"
policy "ci-adverse-event-handling"
permit
subject.principal.role == "Chief Investigator";
subject.principal.purpose == "ADVERSE_EVENT_HANDLING";
policy "ci-statistical-analysis"
permit
subject.principal.role == "Chief Investigator";
subject.principal.purpose == "STATISTICAL_ANALYSIS";
obligation
{ "type": "filterDocuments", "excludeTypes": ["registry"] }
policy "site-investigator-adverse-event-handling"
permit
subject.principal.role == "Site Investigator";
subject.principal.purpose == "ADVERSE_EVENT_HANDLING";
obligation
{ "type": "filterDocuments", "filterSite": subject.principal.site }
policy "site-investigator-statistical-analysis"
permit
subject.principal.role == "Site Investigator";
subject.principal.purpose == "STATISTICAL_ANALYSIS";
obligation
{ "type": "filterDocuments",
"filterSite": subject.principal.site,
"excludeTypes": ["registry"] }
policy "statistician"
permit
subject.principal.role == "Statistician";
obligation
{ "type": "filterDocuments",
"excludeTypes": ["registry", "adverse_event"] }
The Chief Investigator with adverse event handling purpose has no obligation. Full retrieval. The Chief Investigator with statistical analysis purpose has an obligation to exclude the registry. The site investigator always has a site filter, and during statistical analysis also excludes the registry. The statistician excludes both the registry and adverse events.
No policy matches if the role is unrecognized. The combining algorithm is “first or abstain”: if no policy permits, the default decision is DENY. The retrieval does not execute.
Obligations: more than permit or deny
The key difference between the RAG and tool authorization patterns is the use of obligations. In the tool authorization guide, each tool call gets a binary permit or deny. In the RAG guide, the decision is PERMIT with conditions attached. The obligation is a machine-readable instruction that the application must fulfill for the permit to take effect.
If the obligation handler is not registered, or if it fails to apply the filter, the SAPL framework treats the obligation as unfulfilled and converts the PERMIT to a DENY. This is a safety property: a missing or broken filter does not silently grant full access. It fails closed.
This pattern extends beyond document type filtering. SAPL obligations can:
- Rewrite query parameters (cap result limits, adjust similarity thresholds)
- Add metadata filters (restrict by classification level, department, time range)
- Transform retrieved content (redact sensitive fields before they reach the LLM)
- Trigger side effects (audit logging, usage tracking)
The policy decides what happens. The constraint handler executes it. The application code stays clean.
Beyond retrieval filtering: related guides
This guide controls what data reaches the LLM. The AI Tool Authorization and Human-in-the-Loop Approval guides control what the LLM does with it. Both enforce authorization at the tool-calling layer inside the Spring AI application, where the tools are local methods in the same process. The tool authorization guide gates tool calls with binary permit/deny decisions. The HITL guide goes further: the policy returns PERMIT with a condition that pauses execution until a human confirms the action. All three use the same SAPL obligation mechanism, applied to different concerns: query rewriting here, tool gating in tool authorization, and approval workflows in HITL.
The MCP Server Authorization guide takes a different approach. There, the tools are served by a separate MCP server process with its own network boundary. SAPL runs inside the MCP server and guards that boundary via middleware and decorators, controlling what external AI agents can do when they connect. This distinction matters architecturally: application-internal enforcement is appropriate when the application owns the tools, while MCP server enforcement is appropriate when the tools are exposed as a service to multiple clients.
Audit trail
Every retrieval decision is logged with the full context: who made the request, what obligations were attached, and how the search query was rewritten. When a compliance officer asks “who accessed what and why was it allowed,” the audit trail provides a complete answer.
The following is the SAPL decision log for the interaction where Dr. Elena Fischer (Chief Investigator) is performing statistical analysis and asks the AI assistant which participants need to be contacted due to adverse events. The retrieval is permitted, but with an obligation to exclude the participant registry.
Decision: retrieve — PERMIT with obligation
The policy set evaluates four policies. The ci-statistical-analysis policy matches: the user is a Chief Investigator and the purpose is statistical analysis. The decision is PERMIT, but with an obligation to exclude registry documents from the similarity search. The ci-adverse-event-handling policy does not match because the purpose is wrong.
02:49:29.352 [...] --- PDP Decision ---
02:49:29.352 [...] Timestamp : 2026-03-19T02:49:29.352+01:00
02:49:29.352 [...] Subscription :
{
"subject": {
"principal": {
"name": "Dr. Elena Fischer",
"role": "Chief Investigator",
"site": "all",
"purpose": "STATISTICAL_ANALYSIS"
}
},
"action": "retrieve",
"resource": {},
"environment": {
"securityActive": true
}
}
02:49:29.353 [...] Decision : PERMIT
02:49:29.353 [...] Obligations : [{ "type": "filterDocuments", "excludeTypes": ["registry"] }]
02:49:29.353 [...] Documents:
02:49:29.353 [...] rag-retrieval -> PERMIT
02:49:29.353 [...] bypass-when-security-disabled -> NOT_APPLICABLE
02:49:29.353 [...] ci-adverse-event-handling -> NOT_APPLICABLE
02:49:29.353 [...] ci-statistical-analysis -> PERMIT
A single retrieval, a single auditable decision. The decision is PERMIT, but the obligation rewrites the search query to exclude registry documents before it reaches the database. The LLM receives adverse event data, PHQ-9 scores, and the study protocol. It does not receive the participant registry. The audit log shows exactly which policy matched, what obligation was attached, and why the other policies did not apply.
Compare this with the tool authorization audit trail: in the tool authorization guide, the same user interaction produces three separate PDP decisions (one per tool call). In the RAG guide, there is one decision with an obligation that shapes the retrieval. Both are fully auditable. The difference is in the enforcement pattern, not the audit completeness.
This is the human-readable text report. SAPL can also emit these decisions as structured JSON logs, suitable for ingestion by log aggregation and SIEM systems.
Beyond infrastructure-level audit logging, SAPL obligations can model domain-driven constraints and events that are triggered by granted or denied access. A policy can mandate that when a team member accesses sensitive data under a security override, the Chief Investigator is notified automatically for post hoc review. Or that any retrieval of participant registry data creates a compliance record in the trial management system. These are not logging side effects bolted onto the application. They are authorization requirements expressed in policy and enforced by the framework. The same obligation mechanism that rewrites queries and transforms responses can also trigger notifications, create audit records, or initiate review workflows, all driven by the authorization decision rather than scattered through application code.
Run the demo
git clone https://github.com/heutelbeck/sapl-demos
cd sapl-demos/rag-clinical-trial
docker compose up -d
mvn spring-boot:run
Related
- Spring SDK Documentation: the SAPL Spring Boot SDK used in this demo
- AI Tool Authorization: per-tool authorization for the same clinical trial use case
- Human-in-the-Loop Approval: policy-driven approval workflows for sensitive operations
- MCP Server Authorization: the same authorization model for MCP servers